|
I am a second-year Master's student at Xiamen University. My supervisors are Prof. Rongrong Ji and Prof. Yiyi Zhou. I obtained an Honors Bachelor's degree in Computer Science from SZU in 2023, supervised by Prof. Xu Wang. My research interest lies in efficiency optimization for multimodal understanding and generation models. I aim to develop techniques that significantly reduce the resource requirements of multimodal models, making them more suitable for real-world deployment. Looking ahead, I am also interested in exploring reinforcement learning to guide and refine model behavior in complex, interactive environments. |

|
|
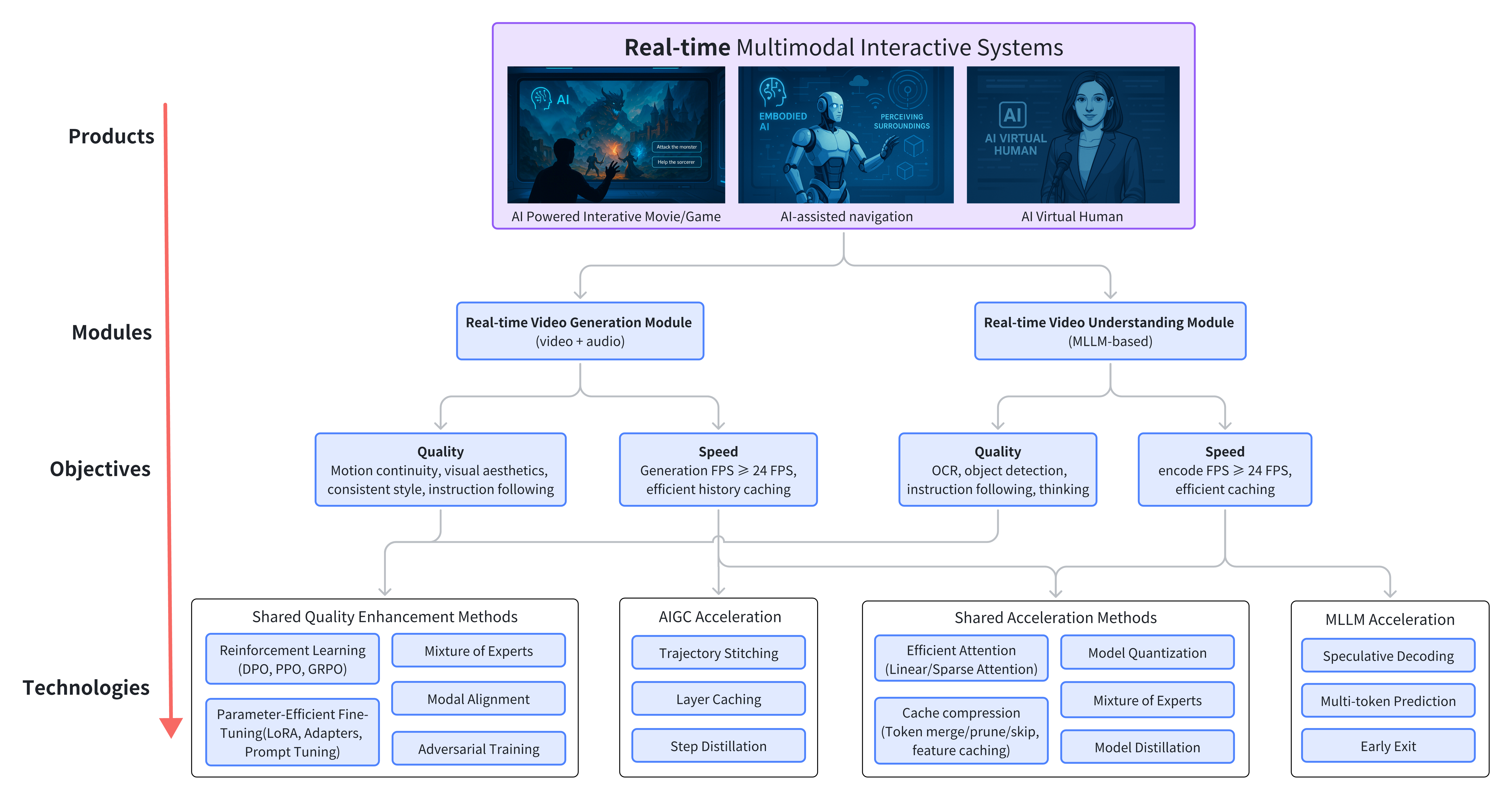
My long-term research goal is to develop systems from the bottom up, aligning low-level algorithmic efficiency with the practical needs of real-world applications.
|
|
|
Check my Google Scholar for the most updated list of publications.
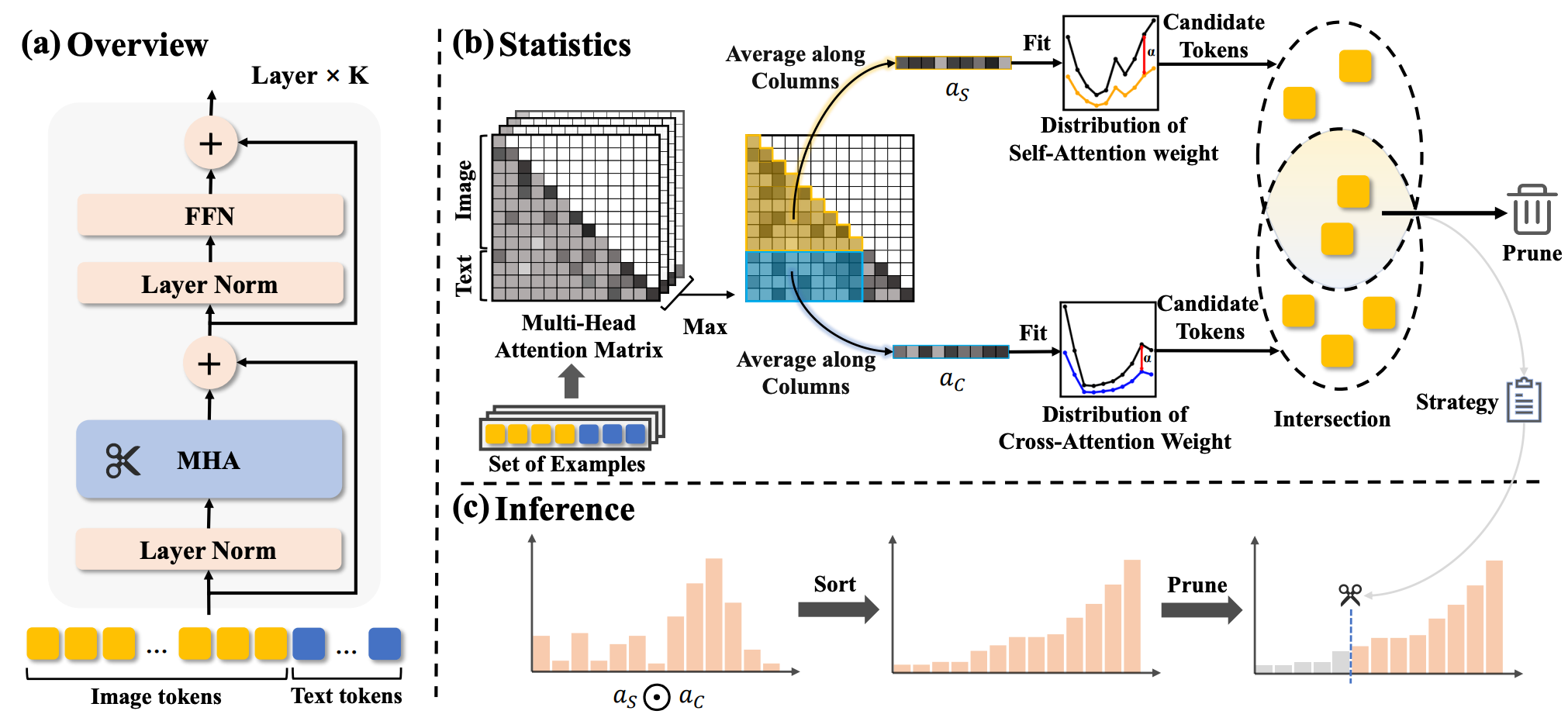
Weihao Ye, Qiong Wu, Wenhao Lin, Yiyi Zhou. AAAI 2025
This paper proposes a training-free visual token pruning method based on attention distribution fitting, significantly boosting inference efficiency of MLLMs.
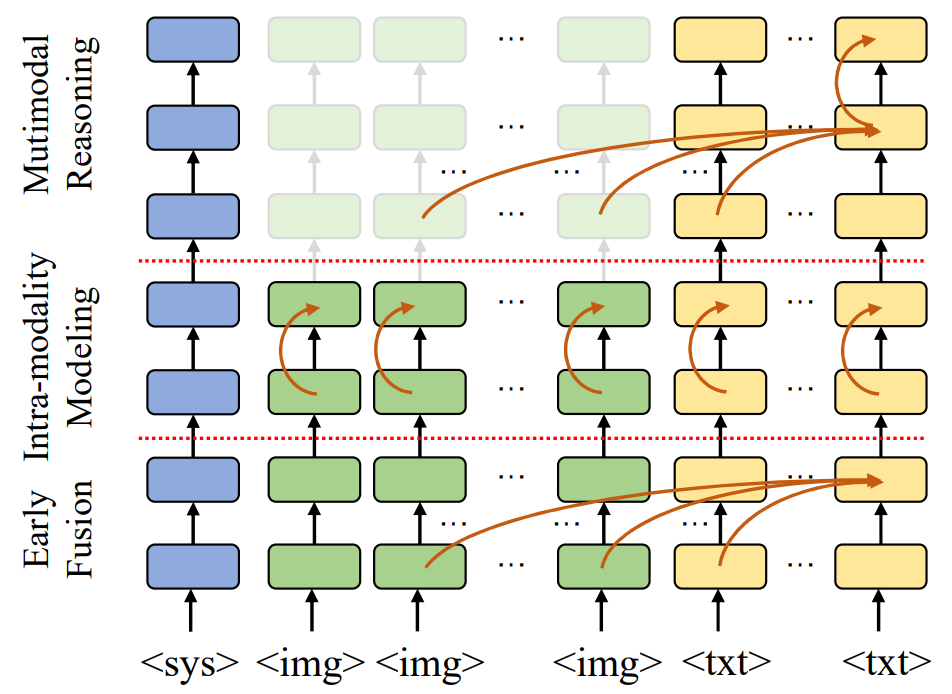
Qiong Wu, Wenhao Lin, Weihao Ye, Yiyi Zhou, Xiaoshuai Sun, Rongrong Ji. NeurIPS 2025 (under review)
This work introduces a dynamic visual token exit mechanism to accelerate MLLMs, along with extensive empirical studies.
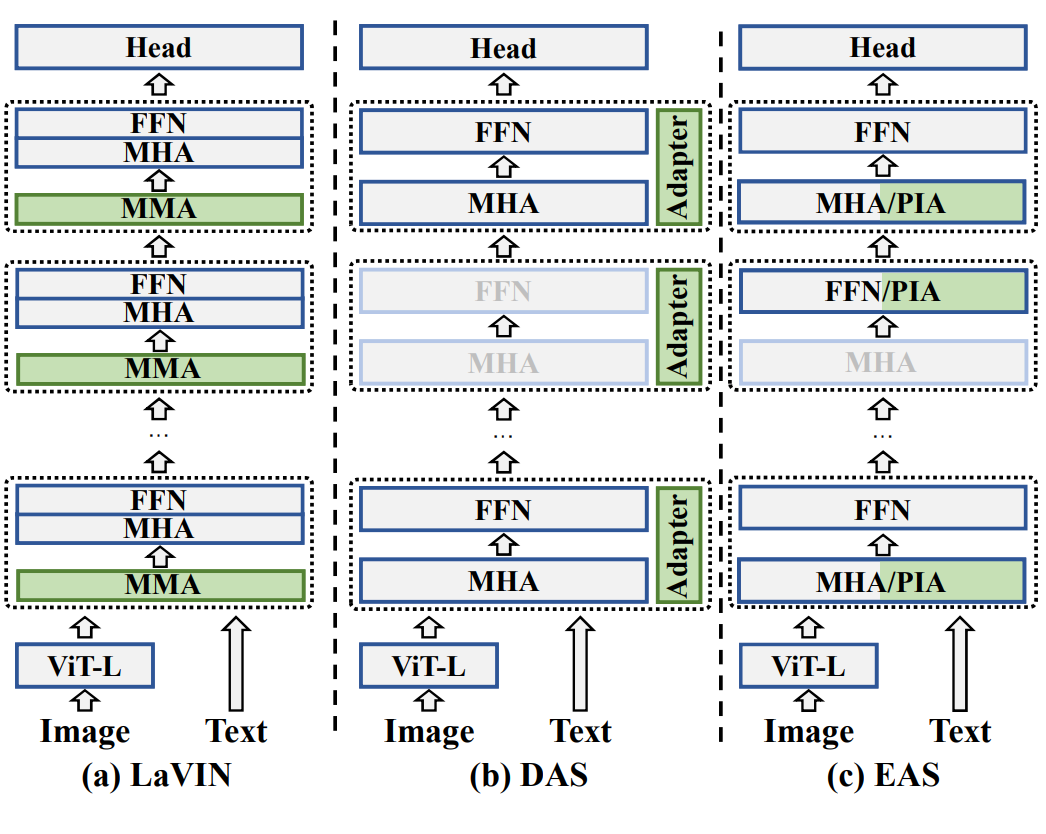
Qiong Wu, Weihao Ye, Yiyi Zhou, Xiaoshuai Sun, Rongrong Ji. IJCV (under review)
This paper proposes an efficient fine-tuning method that skips redundant attention heads using Propagation-Information Adapter (PIA), reducing computational cost.
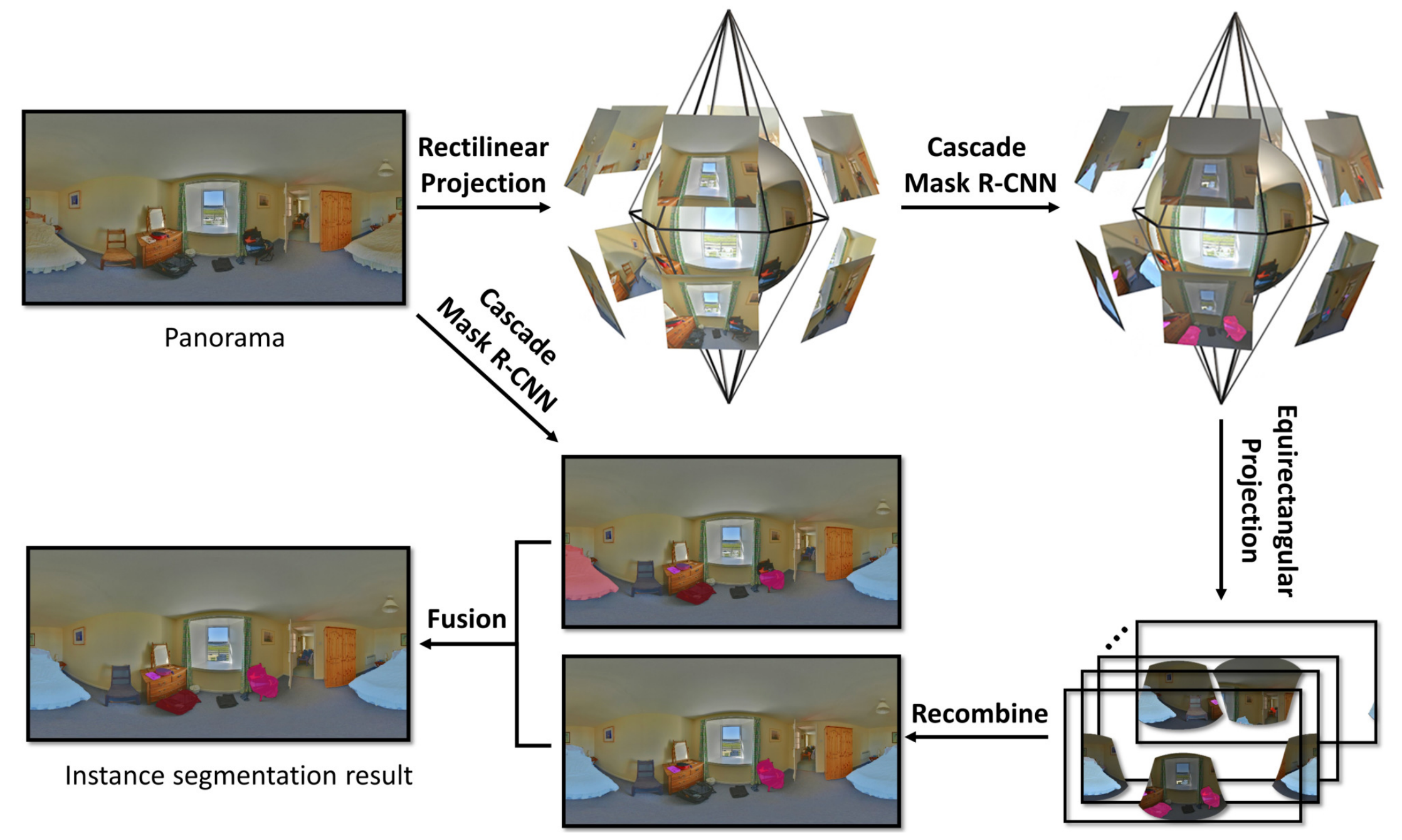
Weihao Ye*, Ziyang Mai*, Qiudan Zhang, Xu Wang. DSAA 2022 (CCF-C)
This work introduces a multi-view joint framework for panoramic instance segmentation, improving segmentation accuracy.
|
|

|
March 2025 – Present I worked as a research intern at ByteDance, where I contributed to the acceleration and optimization of multimodal models used in products such as Doubao and Dreamina. |
|
|